Sometimes, the best projects start with a bad experience.
In my case, it was an attempt to build an internal AI platform together with an external service provider.
On paper, it looked great - but in practice, it was a nightmare: no documentation, no training, a buggy framework, and complete dependency on the vendor for even the smallest change.
It became clear very quickly: this approach could never sustain a platform that needed to support both our internal teams and future customer workloads.
So we took the radical step: start over from scratch, completely vendor-independent.
Phase 1 – Proof of Concept: Start simple, design for scale
The first step was to move away from proprietary tools toward an mostly open, extensible, and maintainable stack. For the PoC, we chose:
- Open WebUI as the frontend — GUI-based configuration that even non-DevOps colleagues could use.
- n8n for workflow automation — open source, extendable, no vendor lock-in.
- PostgreSQL with PGVector as the vector database — already trusted and known within the team.
Kubernetes was part of the long-term vision, but at the time only two colleagues besides myself had hands-on Kubernetes experience. Jumping straight in would have created operational risk.
Instead, we ran the PoC in Docker for fast iteration, built Kubernetes manifests in parallel, and planned to migrate once skills and requirements matured.
After four weeks of testing with 30 users, monitoring via Prometheus & Grafana, load simulations with Locust, and even a disaster recovery drill, the results were clear: no critical bugs, positive feedback, and a stable foundation to build on.
Phase 2 – Architecture & Hardware: From lab to production
With the PoC proven, the focus shifted to building a production-grade platform — reliable for current needs and designed for future scalability and customer deployments.
The architecture remained clean:
- Frontend: Open WebUI
- Workflow Engine: n8n
- Vector Database: PostgreSQL + PGVector
- Authentication: SSO via Entra ID with enforced 2FA
- Networking: for the start pfSense, later moving to Fortigate (+ NGINX Proxy Manager for SSL offloading)
- Monitoring: Prometheus + Grafana
For hardware, we went with a DELL XE server equipped with 4× NVIDIA H200 GPUs.
MIG partitioning allowed us to split workloads efficiently:
- GPU 1: Reasoning LLM (Nemotron 49B v1.5, FP8/FP16)
- GPU 2: Embeddings + reranking, CUDA-accelerated data pipeline
- GPU 3: Customer-specific workloads
- GPU 4: Agentic AI workflows
To make the system design more tangible, here’s a high-level diagram of how data flows through the platform — from the user interaction in Open WebUI, through processing pipelines, vector retrieval, reasoning models, and into agentic workflows.
Color-coded sections highlight different parts of the architecture:
- (Light-)Blue: User-facing components and LLM APIs
- Pink: Data storage and processing layers
- Green: Workflow execution and tool integrations
- Grey diamonds: Decision points in the workflow
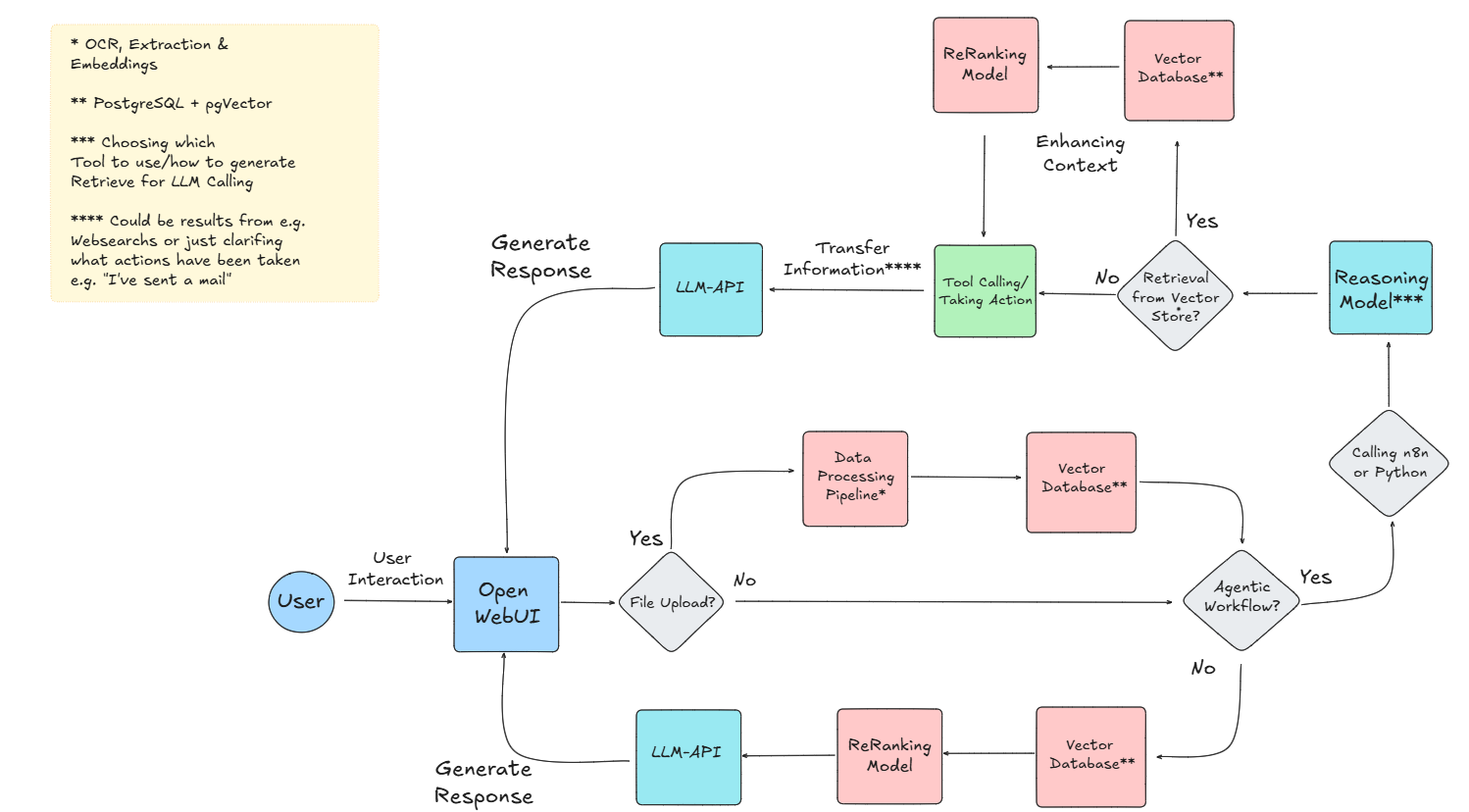
Figure 1: High-level architecture and data flow of the AI platform.
Phase 3 – Operations & Security: Running at enterprise scale
Security and stability were non-negotiable from day one:
- SSO with 2FA and role-based permissions
- VPN-only access to the platform with strict firewall rules
- On-prem hosting within a trusted datacenter certified based on various security standards
- Certificate management via NGINX Proxy Manager
We structured operations across three environments (Development, Staging, and Production) with load testing before every major release and regular disaster recovery simulations.
A key reliability feature: automatic failover to a certified cloud LLM partner in case of on-prem model failure, with the option to deploy Brev instances or use public LLMs (with pseudonymized data).
Results: What changed
- Adoption: Over 250 active users across multiple departments
- Impact: 60% less manual work in specific reporting tasks, better process consistency, and more time for customer-facing tasks
- Use cases: AI-powered onboarding assistant, training simulations, automatic report generation, agentic email triage, and RAG-enabled knowledge search for sensitive data
Final thoughts
What started as a frustrating vendor experience turned into one of the most rewarding projects I’ve worked on.
By combining open-source technology, scalable NVIDIA hardware, and structured operations, we created a stable, secure, and future-ready AI platform — without vendor lock-in, and with room to integrate emerging AI capabilities at speed.